Abstract
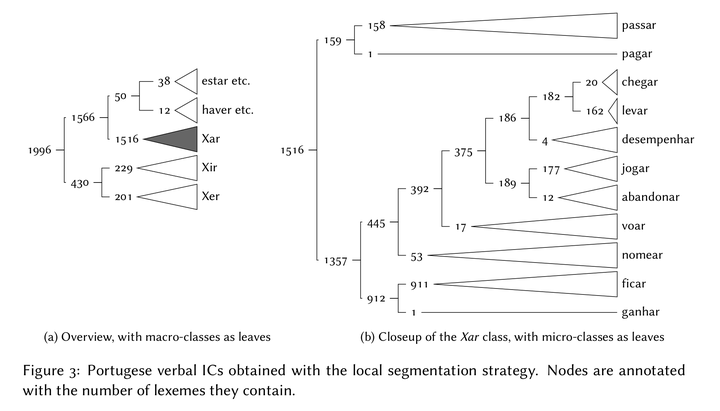
Inflection classes (hereafter ICs) can be defined as groups of lexemes that inflect in similary ways. Descriptions of IC systems take many forms, from flat to hierarchical structures, and depend on theoretical assumptions and on the data at hand. Building on previous work from Brown and Evans (2012), Lee and Goldsmith (2013) and Bonami (2014), we describe an unsupervised strategy for automatically inferring IC systems from paradigmatic data. This allows us to explore the notion of an IC by providing a quantitative and reproducible basis for typological and methodological comparisons and gives us a way of measuring how linguistic theories fit large scale linguistic data. To systematise the linguist’s work in inducing ICs, we face three challenges: (i) defining what form an IC system should take, (ii) deciding what kinds of abstractions should be made from the data in order to infer ICs, (iii) choosing an evaluation metric for candidate ICs and use it to cluster lexemes into an optimal structure of classes.
Please cite my first name as “Sacha” in references to this talk.